
Untertitel sind eine effektive Methode, um die Barrierefreiheit, das Engagement und die Informationsspeicherung während Präsentationen und Live-Events zu verbessern.
Automatische Untertitel wandeln Sprache in Text um, der in Echtzeit auf dem Bildschirm in derselben Sprache wie die Sprache angezeigt wird. ASR – Automated Speech Recognition – ist eine Form künstlicher Intelligenz, die verwendet wird, um diese Transkripte gesprochener Sätze zu erstellen.
Wortfehlerrate
Um die Genauigkeit automatischer Untertitel zu bewerten, ist die am häufigsten verwendete Kennzahl die Wortfehlerrate (WER). Sie misst die Anzahl der Fehler im automatischen Transkript im Vergleich zu den tatsächlich vom Sprecher gesprochenen Wörtern. Im Wesentlichen bietet sie eine Möglichkeit, zu bestimmen, wie gut das automatische System Sprache in Text umwandelt.
Zum Beispiel, wenn 4 von 100 Wörtern falsch sind, würde die Genauigkeit 96% betragen.
The Word Error Rate (WER) is a metric used to measure the accuracy of automated captions. It aligns correctly identified word sequences at a granular level before calculating the total number of corrections necessary to fully align the reference and transcript texts. This includes identifying substitutions, deletions, and insertions. The WER is then calculated by dividing the number of adjustments needed by the total number of words in the reference text. Generally speaking, the lower the WER, the more accurate the voice recognition system.
WER übersieht die Art der Fehler
Die WER-Messung kann irreführend sein, weil sie uns nicht darüber informiert, wie relevant/wichtig ein bestimmter Fehler ist. Einfache Fehler, wie die alternative Schreibweise desselben Wortes (movable/moveable), werden vom Leser nicht häufig als Fehler angesehen, während eine Substitution (exemptions/essentials) möglicherweise stärker wirkt.
WER-Zahlen, insbesondere bei hochpräzisen Spracherkennungssystemen, können irreführend sein und entsprechen nicht immer den menschlichen Wahrnehmungen von Korrektheit. Für Menschen sind Unterschiede in den Genauigkeitsstufen zwischen 90 % und 99 % oft schwer zu unterscheiden.
| Originales Transkript: | ASR-Untertitel-Ausgabe: |
| Zum Beispiel, ich tue mag nur sehr begrenzte Nutzung von dem Grundlagen bereitgestellt, ich möchte einen bestimmten Punkt genauer ausführen, ich befürchte, dass Ich rufe an einzelne Landesparlamente, die Konvention zu ratifizieren, erst nachdem die Rolle des Europäischen Gerichtshofs geklärt wurde, könnte sehr nachteilige Auswirkungen haben. | Zum Beispiel möchte ich ebenfalls nur eine sehr eingeschränkte Nutzung der gewährten Ausnahmen zulassen ich möchte einen bestimmten Punkt genauer ausführen ich befürchte, dass der Aufruf an die einzelnen Staatsparlamente, das Abkommen erst nach Klärung der Rolle des Europäischen Gerichtshofs zu ratifizieren, sehr nachteilige Auswirkungen haben könnte. |
Interprefy's Wahrgenommene Wortfehlerrate
Interprefy hat eine proprietäre und sprachspezifische ASR-Fehlermetrik namens Perceived WER entwickelt. Diese Metrik zählt nur Fehler, die das menschliche Verständnis der Sprache beeinträchtigen, und nicht alle Fehler. Wahrgenommene Fehler liegen in der Regel unter dem WER, manchmal sogar um bis zu 50 %. Ein wahrgenommener WER von 5‑8 % ist für den Benutzer normalerweise kaum bemerkbar.
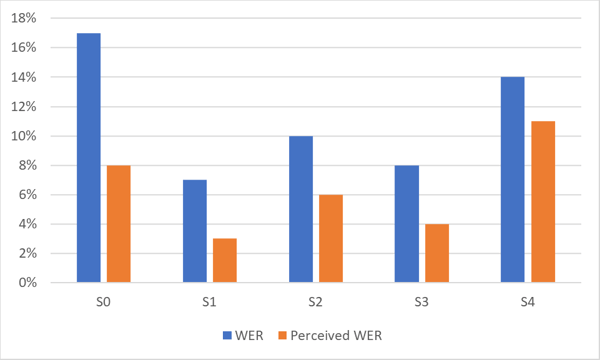
Das untenstehende Diagramm zeigt den Unterschied zwischen WER und wahrgenommener WER für ein hochpräzises ASR-System. Beachten Sie den Leistungsunterschied für verschiedene Datensätze (S0‑S4) derselben Sprache.
Wie in der Grafik gezeigt, ist der von Menschen wahrgenommene WER oft deutlich besser als der statistische WER.
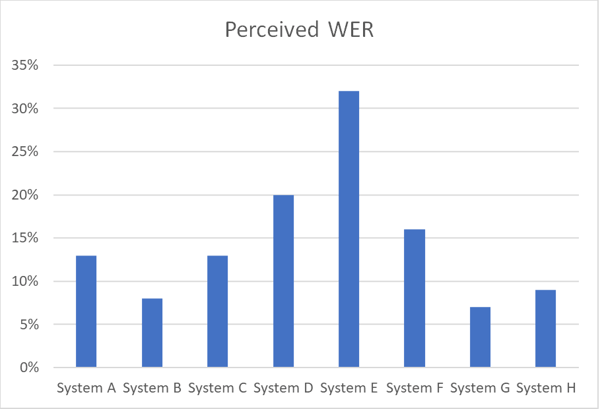
Das untenstehende Diagramm veranschaulicht Unterschiede in der Genauigkeit zwischen verschiedenen ASR‑Systemen, die auf demselben Sprachdatensatz in einer bestimmten Sprache mit wahrgenommenem WER arbeiten.
Wesentliche Faktoren, um unglaublich präzise Untertitel zu erreichen
Es gibt drei wichtige Punkte, die Sie berücksichtigen sollten:
- Verwenden Sie eine erstklassige Lösung: Statt irgendeine Standard-Engine zu wählen, die alle Sprachen abdeckt, entscheiden Sie sich für einen Anbieter, der für jede Sprache in Ihrer Veranstaltung die bestverfügbare Engine nutzt.
- Optimieren Sie die Engine: Wählen Sie einen Anbieter, der die KI mit einem maßgeschneiderten Wörterbuch ergänzen kann, um sicherzustellen, dass Markennamen, ungewöhnliche Namen und Abkürzungen korrekt erfasst werden.
- Stellen Sie sicher, dass die Audioeingabe von hoher Qualität ist: Wenn die Audioeingabe schlecht ist, kann das ASR-System die Ausgabequalität nicht erreichen. Stellen Sie sicher, dass die Sprache laut und deutlich erfasst wird.